基础 & 工具 & 验证
客户端
- playwright+python ✅
- 各类验证识别
- 图形处理,模式识别 --- 效果不佳 ❌
- yolov8n,训练小模型。50 张训练图片,验证集测试,检出有效 90% 以上。 ⏰ 20251030 ✅
- 网站点击和交易,抓取 html 回填。 douban 爬虫项目验证可行。 ✅
AIcoding
- copilot,claude ✅
大模型接入
- API 方式验证。✅
训练和回测
[[训练回测]] -- training & backtest
系统搭建
QLib
#macmini
git clone https://github.com/microsoft/qlib.git
export PATH="$HOME/Library/Python/3.9/bin:$PATH"
/Library/Developer/CommandLineTools/usr/bin/python3 -m pip install --upgrade pip
python3 setup.py install\
pip install setuptools setuptools_scm wheel
pip install --upgrade setuptools wheel setuptools_scm
#创建虚拟环境
cd ~/
python -m venv venv
source venv/bin/activate
#依赖
cd quant/qlib
pip install -U pip setuptools wheel setuptools_scm
pip install pyqlib[all]
#验证
python -c "import qlib, sys; print(qlib.__file__); print(qlib.__version__)"
python scripts/get_data.py qlib_data --target_dir ~/.qlib/qlib_data/cn_data --region cn
python -c "import lightgbm; print('LightGBM loaded successfully!')"
#运行
qrun benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml
#继续安装依赖
brew install libomp
pip install lightgbm --no-binary :all:
pip install "urllib3<2.0"
pip install catboost xgboost torch
brew install cmake libomp
pip install baostock yahooquery openpyxl xlrd
#下载数据
python scripts/data_collector/cn_index/collector.py ~/.qlib/qlib_data/cn_data csi300
python scripts/data_collector/cn_index/collector.py ~/.qlib/qlib_data/cn_data csi500
qrun benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml
#可视化
~/venv/bin/mlflow ui --backend-store-uri ./mlruns
#---
#copy到 macbook,出错
(venv) gavin qlib % python scripts/get_data.py qlib_data --target_dir ~/.qlib/qlib_data/cn_data --region cn
# 1. 卸载虚拟环境里的旧 qlib
pip uninstall -y qlib pyqlib
# 2. 切换到你自己的源码路径
cd /Users/gavin/quant/qlib/
# 3. 用开发模式安装(不会覆盖你的改动)
pip install -e .
训练
source ~/venv/bin/activate && qrun examples/benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml
#保持 examples 中的数据不动,copy 到 scripts 中修改,git 不上传 examples 目录
source ~/venv/bin/activate && qrun scripts/benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml可视化
#使用 sqlite
gavin mini qlib % mlflow ui --backend-store-uri sqlite:///mlflow.db在examples/benchmarks/LightGBM/workflow_config_lightgbm_Alpha158.yaml中增加:
provider_uri: "~/.qlib/qlib_data/cn_day"
region: cn
exp_manager:
class: MLflowExpManager
module_path: qlib.workflow.expm
kwargs:
uri: "sqlite:///mlflow.db"
default_exp_name: "workflow"### mds cpu 105%
### 临时彻底关闭 Spotlight 索引
sudo mdutil -a -i off
#完成后打开
sudo mdutil -a -i on #参数调整 model: LGBModel
learning_rate: 0.05 #默认 0.2,它控制模型在每一轮迭代中更新的步长大小,降低增加迭代次数
lambda_l1: 300 #默认205.6999
lambda_l2: 800 #默认580.9768
max_depth: 8
num_leaves: 210
num_threads: 10 #默认 20,调低,否则 PC 上跑会资源不足出错learning_rate: 减半学习率 → 树数翻倍,模型效果会更稳。
| 场景 | 推荐取值 | 说明 |
|---|---|---|
| 快速实验、调参初期 | 0.1–0.2 | 收敛快,但可能略过拟合 |
| 稳定生产模型 | 0.05–0.1 | 泛化较好 |
| 高噪声数据或复杂特征 | 0.01–0.05 | 更稳健,但训练慢 |
| 配合大树数(num_boost_rounds) | 0.005–0.02 | 小步多走,效果更细腻 |
lambda_l1,lambda_l2,$\text{Regularization} = \lambda_{L1} \sum |w_i| + \lambda_{L2} \sum w_i^2$
- lambda_l1:L1 正则化系数,对每个叶节点权重 w_i 加绝对值惩罚。使部分叶节点权重变为 0,实现稀疏化。减少特征数量,提高泛化能力。
- lambda_l2:L2 正则化系数,对每个叶节点权重 w_i 加平方惩罚。平滑所有权重,防止过大波动。减少过拟合,让模型更“稳”。
收益
python scripts/visualization/plot_nav.py \
--run-path mlruns/975782748948748134/aa8d1f11ee8944d6b937113df1075071 \
--output nav.png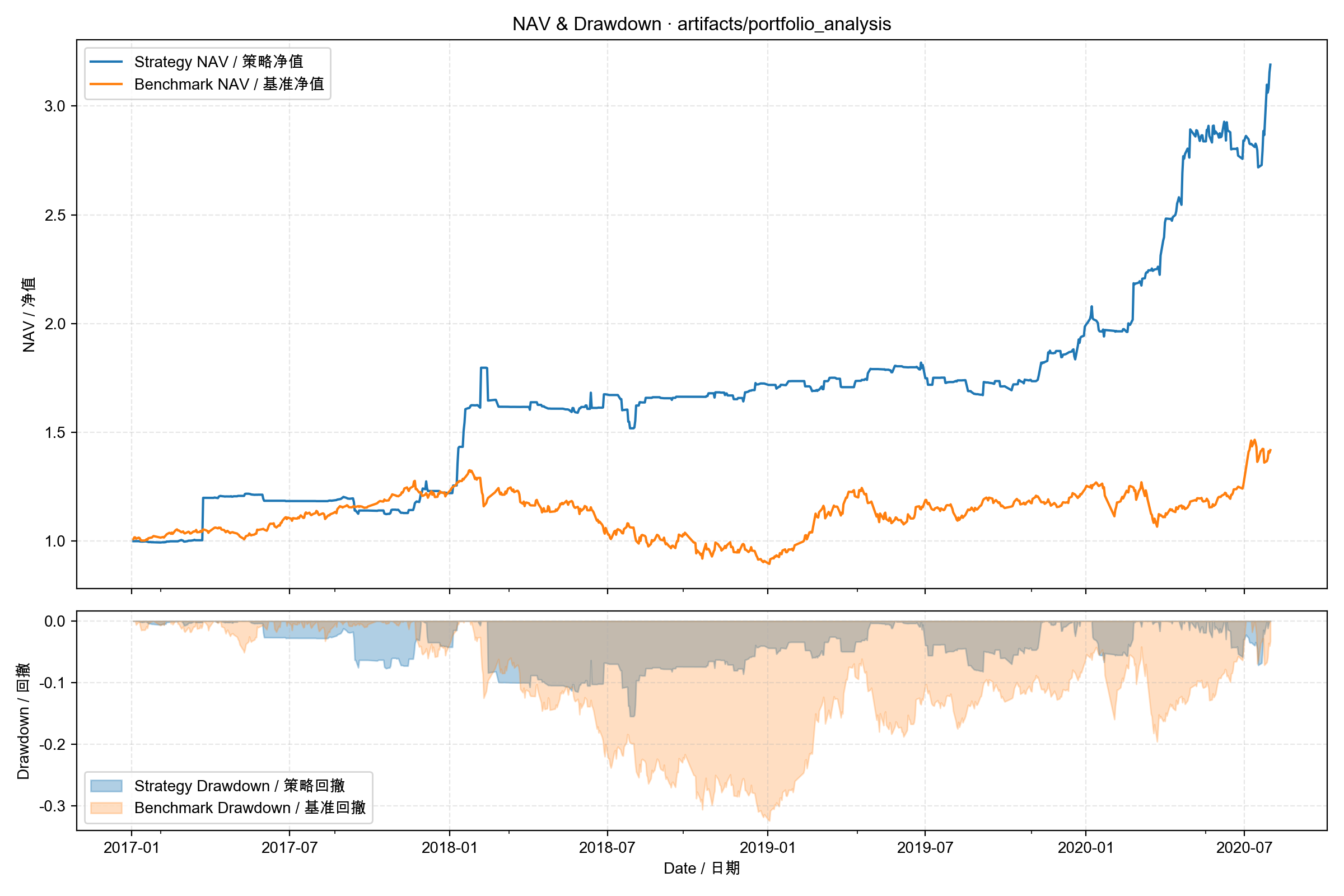
数据
闲鱼2012~2025 日交易数据
##########❌❌ **改为在一个文件夹下递归处理,否则生成的~/.qlib/qlib_data/cn_day/instruments/all.txt文件会被最后一次 dull_bin.py 执行覆盖。**
gavin mini data % pwd
/Users/gavin/quant/data
gavin mini data % ls
1-500 2001-2500 3501-4000 5001-5500 沪深股票大盘数据
1001-1500 2501-3000 4001-4500 501-1000
1501-2000 3001-3500 4501-5000 5501-5715
#csv 数据转为 qlib 可用的 bin 数据
python scripts/dump_bin.py dump_all --data_path ../data/1001-1500 --qlib_dir ~/.qlib/qlib_data/cn_day --freq day --date_field_name 交易日期 --file_suffix .csv --include_fields '开盘价,最高价,最低价,收盘价,涨跌额,涨跌幅(%),成交量(手),成交额(千元),换手率(%),复权因子'python scripts/dump_bin.py dump_all --data_path ../data/stock --qlib_dir ~/.qlib/qlib_data/cn_day --freq day --date_field_name 交易日期 --file_suffix .csv --include_fields '上市日期,交易日期,开盘价,最高价,最低价,收盘价,前收盘价,涨跌额,涨跌幅(%),成交量(手),成交额(千元),换手率(%),换手率(自由流通股),量比,市盈率,市盈率(TTM,亏损的PE为空),市净率,市销率,市销率(TTM),股息率(%),股息率(TTM)(%),总股本(万股),流通股本(万股),自由流通股本(万股),总市值(万元),流通市值(万元),今日涨停价,今日跌停' --symbol_field_name "TS代码" --max_workers 4
### 不能再跑这条,否则前面的会被覆盖
python scripts/dump_bin.py dump_all --data_path ../data/沪深股票大盘数据 --qlib_dir ~/.qlib/qlib_data/cn_day --freq day --date_field_name 交易日期 --file_suffix .csv --include_fields '交易日期,开盘价,最高价,最低价,收盘价,前收盘价,涨跌额,涨跌幅(%),成交量(手),成交额(万元),当日总市值(十万元),当日流通市值(十万元),当>日总股本(万股),当日流通股本(万股),当日自由流通股本(万股),换手率(%),换手率(自由流通股),市盈率,市盈率(TTM),市净率' --symbol_field_name "股票代码" --max_workers 4- dump_all:scripts/dump_bin.py 提供的子命令,表示执行“全量转换”,会在目标目录中生成新的日历、标的、特征文件。
- --data_path ../data/1-500:原始 CSV 数据所在的路径。脚本会遍历该目录下所有后缀匹配的文件。
- --qlib_dir ~/.qlib/qlib_data/cn_day:转换输出目录。脚本会在此目录下创建 calendars/、instruments/、features/ 等结构。
- --freq day:数据频度,day 表示日线;如有 1 分钟数据可改成 1min。
- --date_field_name 交易日期:CSV 中代表日期的列名;脚本会据此解析日期并对齐日历。
- --file_suffix .csv:遍历文件时匹配的后缀,确保只处理 CSV。
- --include_fields '开盘价,最高价,最低价,收盘价,涨跌额,涨跌幅(%),成交量(手),成交额(千元),换手率(%),复权因子':指定需要写入特征文件的列名(用逗号分隔)。如果不设置,会默认导出所有列;设置后可避免把无关字段写入
每个标的的特征文件(features/<code>/<field>.day.bin)也会重新写一遍。脚本内部对 dump_all 模式使用的是覆盖写(numpy.tofile 默认以二进制写新文件),不会把数据追加到已有 .bin 上,所以不会产生重复或膨胀。
数据可视化
接口取(需调研确定数据源⛳️ )
| 平台 | 优点 | 缺点 | 是否支持分钟级数据 | 费用级别 | 是否适合实盘 | 适合场景 |
|---|---|---|---|---|---|---|
| AKShare | 开源免费;支持多市场(股票、期货、外汇、基金、加密等);接口多且更新快。 | 数据稳定性、延迟、商业支持不如专业接口;部分源为网页抓取。 | ✅ 支持(1/5/15/30/60 分钟) | 免费 | ❌ 需自行验证稳定性 | 学习、研究、策略原型、低频验证。 |
| Baostock | 免费开源;专注 A 股历史行情+财务;接口简单易用。 | 分钟数据覆盖有限(近 5 年左右);无 tick/盘口。 | ⚠️ 仅部分支持(近年分钟) | 免费 | ❌ 不建议实盘 | 日线/分钟线原型、小规模研究。 |
| Tushare Pro | 数据种类最丰富(行情、财务、期货、数字币、资金流等);SDK 完善;数据清洗较好。 | 积分收费机制复杂;调用量大成本快升;部分实时数据延迟。 | ✅ 支持(1/5/15/30/60 分钟) | 💰 中等(数百~数千元/年) | ⚠️ 适合回测或轻实盘 | 中频(日内/小时)策略,价量+基本面结合研究。 |
| JQData(JoinQuant) | 专业量化平台;API 稳定;分钟/日线/期货均支持;适配实盘。 | 成本较高;高级数据需企业版;极低延迟不及交易所直连。 | ✅ 支持(1 分钟级) | 💰💰 中高 | ✅ 稳定可用于实盘 | 机构研究、实盘策略、需要稳健行情服务。 |
| BigQuant | 集成股票/期货/财务/另类数据;AI 因子研究框架;云端回测。 | 更偏研究平台;原始行情接口灵活性弱;价格较高。 | ⚠️ 支持(分钟级可订阅) | 💰💰💰 较高 | ⚠️ 研究/测试为主 | 因子研究、AI 模型训练、多市场实验。 |
| UData | 提供部分宏观及金融数据;界面简单;上手门槛低。 | 公开接口少;稳定性未知;无详细文档。 | ❌ 不支持分钟级行情 | 免费 / 不详 | ❌ | 入门研究、教育演示。 |
| QStock | Python 封装轻量;易上手;可快速获取基础行情。 | 稳定性较差;数据更新滞后;覆盖面小。 | ⚠️ 仅部分支持 | 免费 / 低 | ❌ | 初学者体验、教学、小型策略原型。 |
采集
tushare 5000积分,TUSHARE_TOKEN=2876ea85cb005fb5fa17c809a98
舆情因子
回测
回测框架:backtrader, rqalpha, zipline
交易
环境&硬件
一阶段
MAC上验证
问题记录
过程记录
学习
波动率概念在量化中很重要,原因波动率是所有因子的综合的结果。很多因素很难去预测或评估,比如市场心理,但他会体现的波动走势上。波动率是一些列散点的均方差$\sigma = \sqrt{\frac{1}{n}\sum_{i=1}^{n}(x_i - \mu)^2}$,表示这些散点偏离均值的严重程度。均方差的概念很有用,以前做数据的线性拟合,就是计算均方差$\sigma$,比较拟合程度。
量化任务是建立标的运行模型,以预测标的走势。 按一价理论,市场有效性理论,一个自由的公开的充分博弈的市场,不存在无风险套利的机会。 因为假定存在这样的机会洼地,会迅速的的被填平。
现实情况远比理论复杂,交易心理学和信息不对称永远存在。这是量化的机会。
模型是对现实的抽象,不同因子反映显示的一个侧面。 比如:Black-Scholes模型$\frac{\partial C}{\partial t} + rS\frac{\partial C}{\partial S} + \frac{1}{2}\sigma^2S^2\frac{\partial^2 C}{\partial S^2} = rC$,期权价格C是“标的价格S”和“剩余时间t”的二元函数,分别考虑了时间、股票价格、股票价格波动对期权价格的影响。偏微分的本质物理含义就是不考虑其他因素下,某个单位分母因素对分子因素的影响。通过这个方程,代入市场已知因素就能得出未来公允的期权价格 C。
BS 模型很理想,但过于简化, 太粗暴。所以,在此基础上,又有赫斯顿模型(Heston Equation)。C(S, v, t) 的偏微分方程( S 为标的价格, v 为瞬时波动率, t 为时间),形式如下:$\frac{\partial C}{\partial t} + rS\frac{\partial C}{\partial S} + \left( \kappa(\theta - v) - \lambda v \right)\frac{\partial C}{\partial v} + \frac{1}{2}\sigma_v^2 v\frac{\partial^2 C}{\partial v^2} + \frac{1}{2}\sigma_S^2 S^2\frac{\partial^2 C}{\partial S^2} + \rho \sigma_S \sigma_v S \sqrt{v}\frac{\partial^2 C}{\partial S \partial v} = rC$ r :无风险利率(同Black-Scholes); $\kappa$ :波动率回归速度(越大,波动率越易回到均值 $\theta$ );$\theta$ :波动率长期均值(市场隐含的平均波动水平); $\lambda$ :波动率风险溢价(补偿投资者承担波动不确定性的收益);$ \sigma_v$ :波动率的波动率(波动本身的波动幅度,即“波动的波动”);$ \rho$ :标的价格与波动率的相关性(通常为负,比如股票跌时波动涨); • 交叉偏导项 $\frac{\partial^2 C}{\partial S \partial v}$ :标的价格与波动率的联动对期权价格的影响。 将波动率视为随机过程(遵循均值回归),更贴合实际市场的“波动率微笑”(不同执行价期权隐含波动率不同)和“波动率聚类”(高波动后易跟随高波动)现象。
问题是,这些随机过程因素无法确定计算,只能通过蒙特卡洛方式进行模拟 --- 随机分配种子,每一个路径给一个随机过程,最后拟合出一套因子。
蒙特卡洛是一种方案,目的是获得通过理论分析确定的因子。 现在比较主流的做法是结合机器学习,机器学习不管理论怎么分析,一切用数据来讲话。通过数据洞察关键因子,市场因素综合反映在这些因子上。 人可能很难洞察这些因子为什么是这个样子,没有什么解释度。传统模型则不同,首先是要有解释力,再在市场上验证有效性。 机器学习不同,随时变化。变化的依据是数据。就像 AI 象棋高手,一些列的国手严重的臭手,却能赢得比赛。目标是赢得比赛。而不是解释世界。
以后的情况可能是,量化交易师也只是操作员。学习理解使用数学模型可能没有那么必要。通过数据的东西,AI 帮你找到一堆有效的因子。至于这堆因子什么意思,无需专注,也无法解释。
现在主流的几个机器学习模型:XGBoost,LSTM,LightGBM。先试试 XGBoost,LightGBM。基于 QLib。
知识体系&调研
概念
指标
多因子
形态模式
想法
- 以小窗口(如3天、1天甚至分钟级别的K线形态)作为形态训练数据,关联后续涨跌。AI训练不同形态下涨跌,做出高中低频的买卖决策。可行性❓ 海量小窗口和形态,无法处理❓ 可以提供形态模板,先做过滤,以过滤后的数据做训练。似乎可行,待验证 💡
- 形态模式识别 + 多因子。
- 大概率会存在过拟合问题❓训练集之外找验证集。
参考
书籍
- 《波动率微笑》
- 《主动投资组合管理》
论文
- A Hybrid Framework for Algorithmic Trading: Combining Deep Learning Trend Prediction with Candle Stick Pattern Recognition
- Data-Driven Measures of High-Frequency Trading
- 20181101-海通证券-金融工程专题报告:高频量价因子在股票与期货中的表现
- 20221118-国金证券-金融工程专题报告:Alpha掘金系列之二,基于高频快照数据的量价背离选股因子.pdf
- 2023中国量化白皮书