{kind=link}
Kindle Manager
找不到好用的APP,本意自写自用兼练手,零星写了几天觉得还趁手
后端 python, 前端GUI PySide2
关于打包
研究了一个周末python打包工具,试用了py2app,pyinstaller,问题始终没有解决,艰难放弃!!! -- 20200621
解决MAC打包和移植问题, 各种查询和试错,前后花的时间应该超过写这个软件的时间 参见总结 -- 20200705
CHANGE LOG
ChangeLog 这里记录迭代过程,及过程中记录的一些功能的想法,
以及python使用中的一些问题lession learning
软件下载
- Windows: kmanapp_v1.1.1
- MacOs: link
使用说明
大体功能:
- 连kindle后会自动识别设备
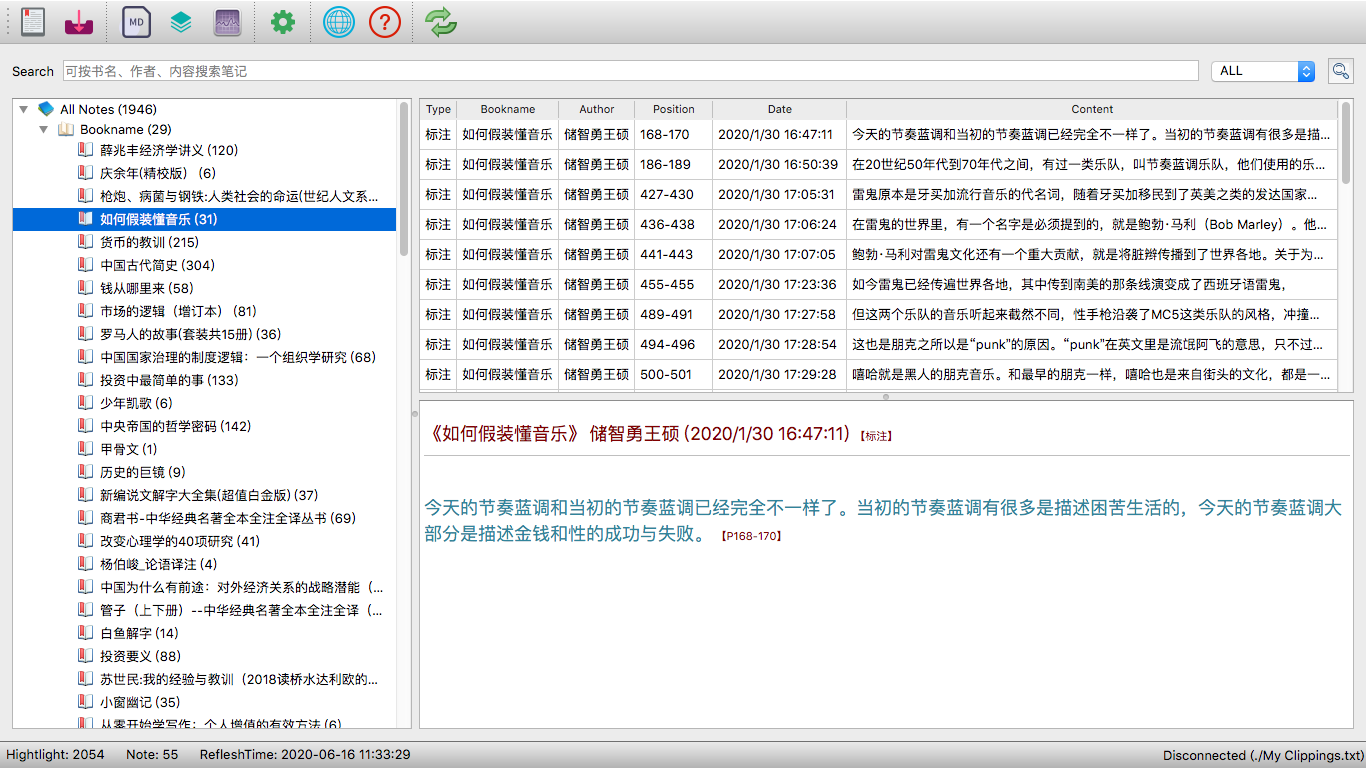
- 读取kindle/本地笔记,获取标注和剪贴文章。一键导入/刷新/同步
- 会对笔记做一些去重及备注匹配等修正动作。
- 按书本标题作者搜索,默认模糊搜索,并导出markdown等格式标注
- 一些导入导出及回写等功能,回写/修改暂未做,自己不太喜欢,担心存储内容会乱
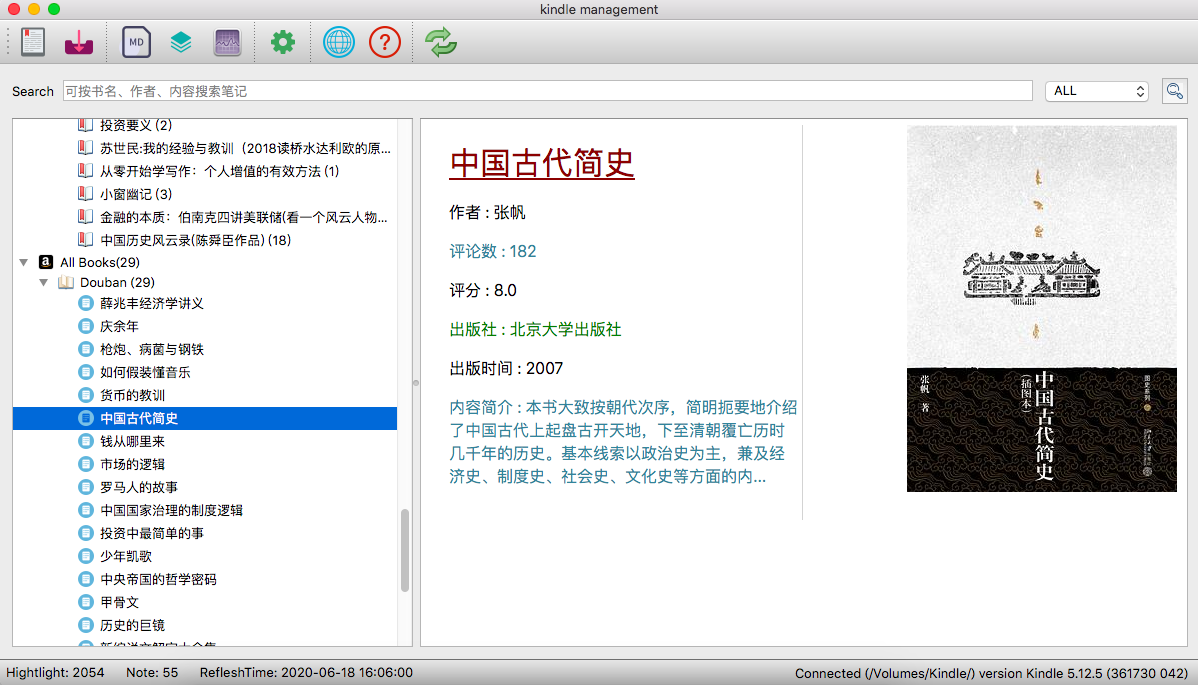
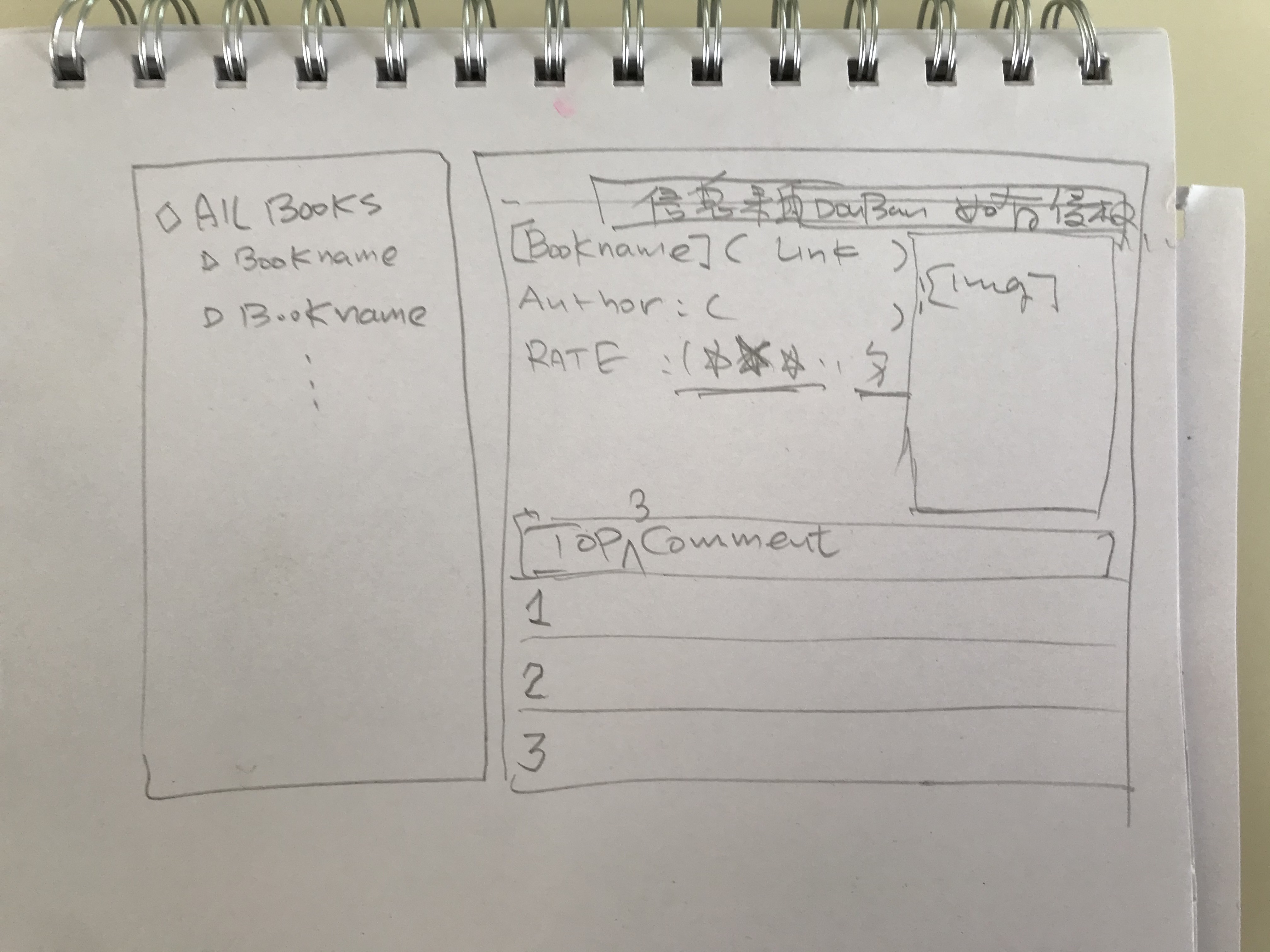
- 写的过程中临时想到的一些功能,比如在线获取豆瓣/amazon信息关联

版权等问题
-
对于自己笔记涉及的书,会去douban/amazon,爬取少量bookinfo,不知算不算侵权
-
图标来自findicons,不知有没有版权
-
所有code系本人码出,如有借用,会在注释中以refrence说明
-
其他问题,望告知, gavin's mail address
-
所有内容解析都采用正则实现,没有使用xpath,beautifulsoap。据说regexp更快, 当然对我来说生产效率的原因,有兴趣可以看代码。补充:关于regexp&xpath&beautifulsoap效率分析,本人做了对比,结果很出我的意料,参见
-
不得不说python的数据结构比perl难用一些,不过defaultdict用趁手了,也还可以
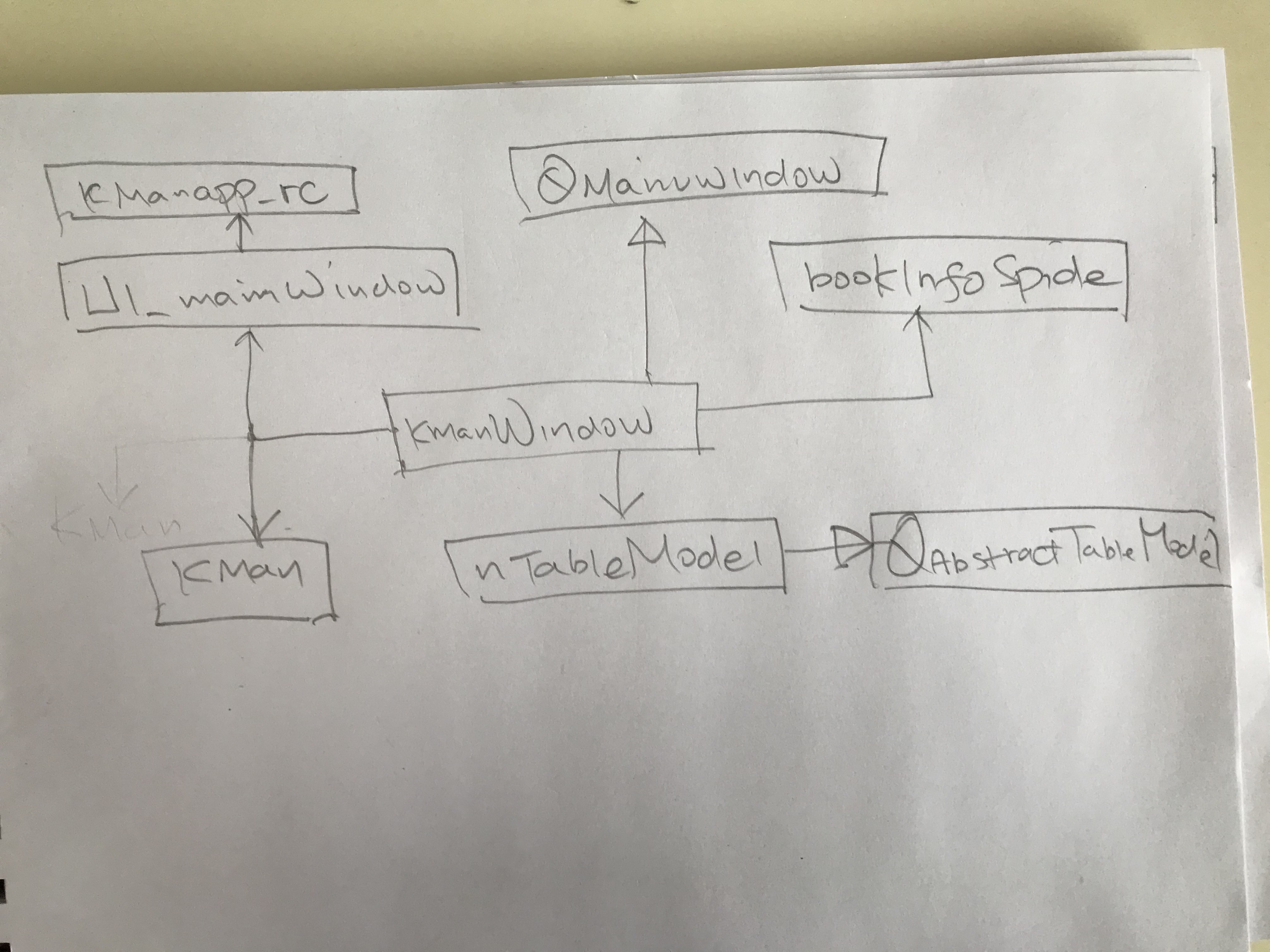
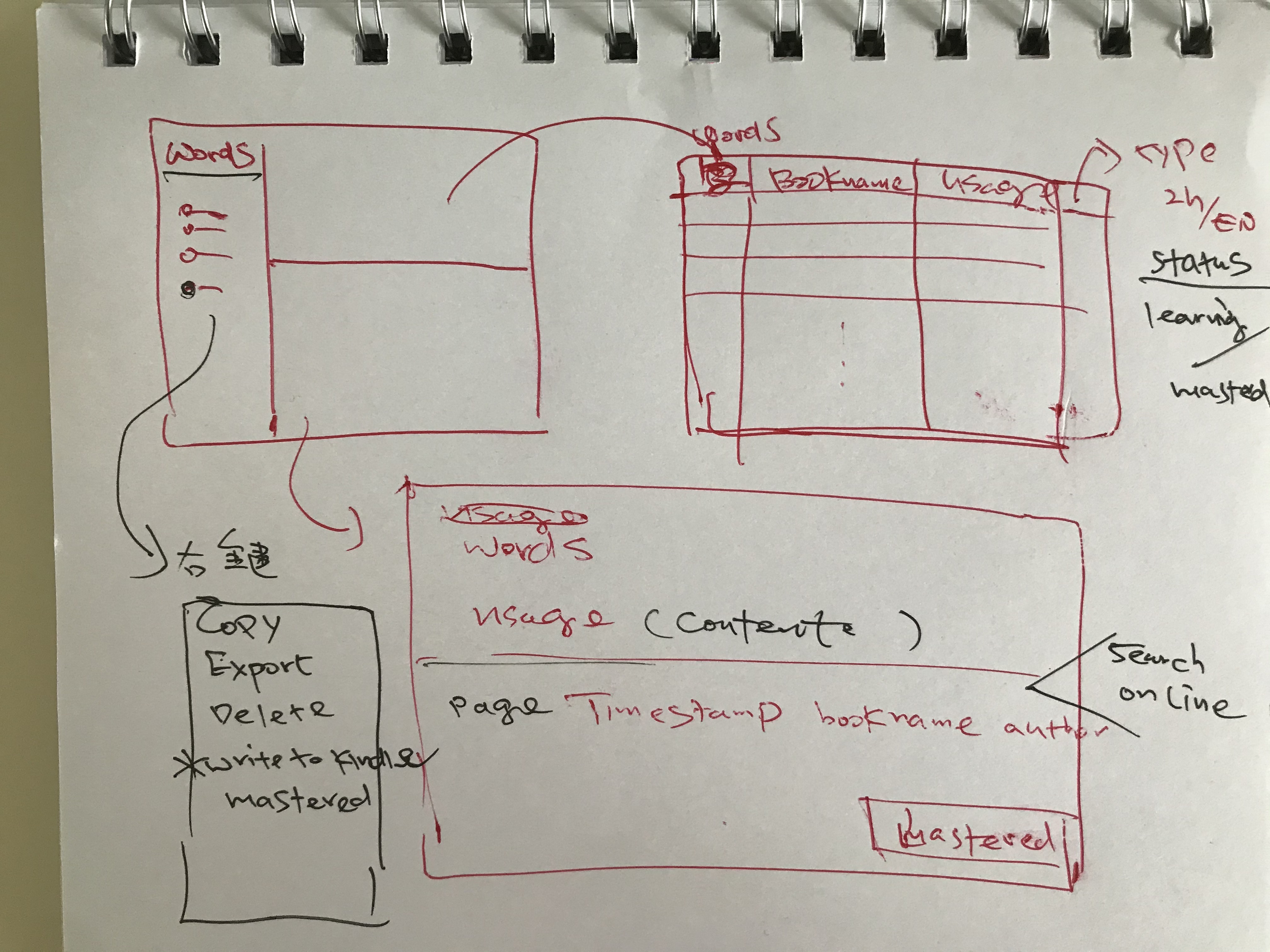
类图
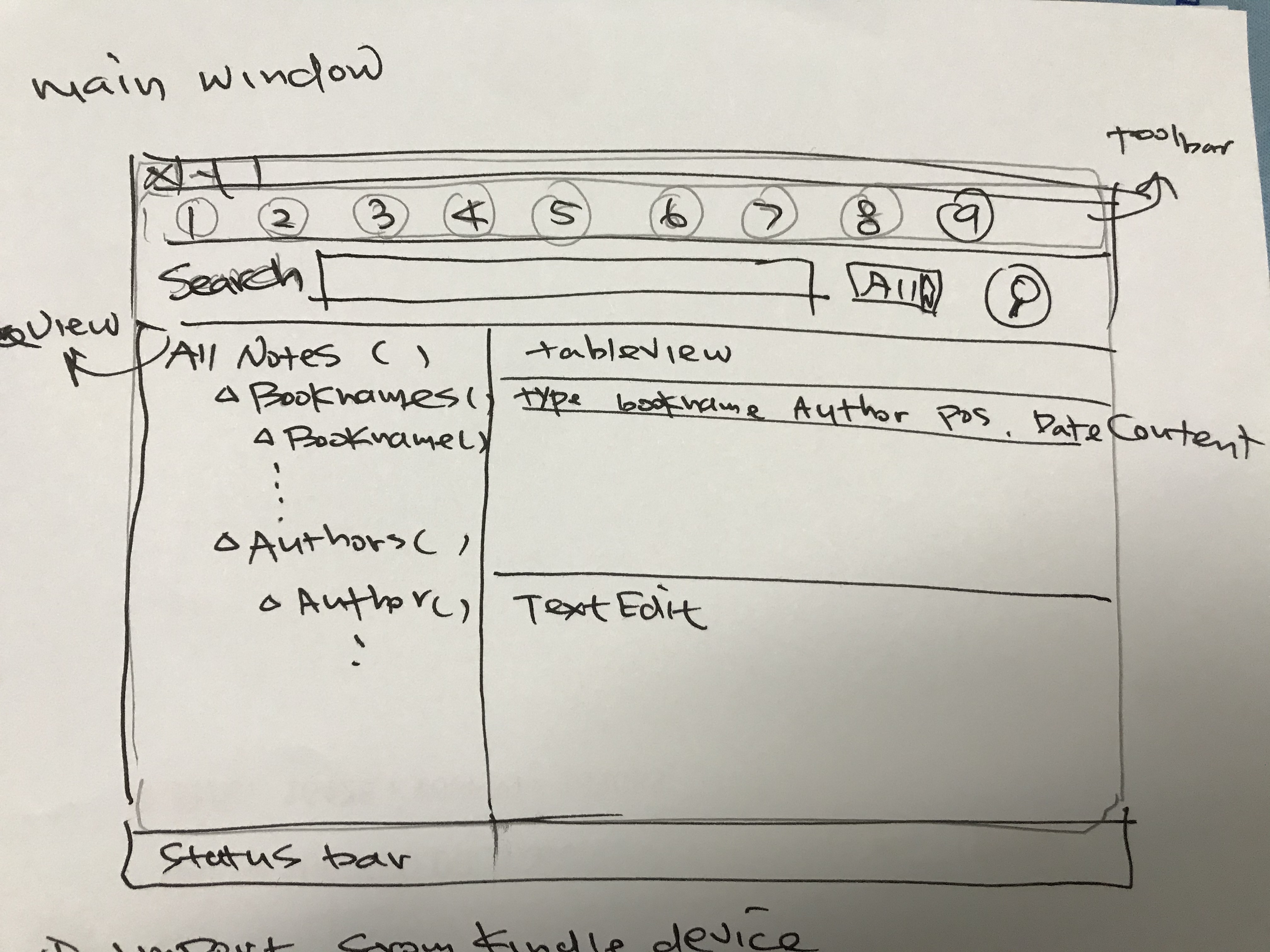
GUI Design


格式说明
3种类型
书签
格式为:
庆余年(精校版) (猫腻)^M
- 您在位置 #33260 的书签 | 添加于 2020年1月12日星期日 下午10:37:10^M
^M
^M
标注
格式为:
<feff>薛兆丰经济学讲义 (薛兆丰)^M
- 您在位置 #1408-1410的标注 | 添加于 2020年1月13日星期一 上午8:11:05^M
^M
么到底什么叫边际?边际就是“新增”带来的“新增”。 例如,边际成本就是每新增一个单位产品所需要付出的新增成本;边际收入是每多卖一个产品能够带来的新增收入;边际产量是每新增一份投入所带来的新增产量;边际效用是每消耗一个单位的商品所能带来>的新增享受。^M
笔记
笔记比较特殊,笔记是与标注连在一起的。表示该笔记是在该标注上完成的。
<feff>薛兆丰经济学讲义 (薛兆丰)^M
- 您在位置 #4284-4286的标注 | 添加于 2020年1月30日星期四 上午10:23:58^M
^M
一个国家很大,贫富有差距,并非每个学校和家长都能负担得起这样标准的校车。标准太高,就会逼着很多学校,尤其是农村的学校放弃提供校车,家长们就只能使用安全性能更低的交通工具,比如自己骑自行车或雇用黑车等,结果是孩子们享受到的安全保障反而降低了。^M
==========^M
<feff>薛兆丰经济学讲义 (薛兆丰)^M
- 您在位置 #4286 的笔记 | 添加于 2020年1月30日星期四 上午10:26:10^M
^M
是山寨 假货 问题^M
==========^M
<feff>薛兆丰经济学讲义 (薛兆丰)^M
- 您在位置 #4286 的笔记 | 添加于 2020年1月30日星期四 上午10:26:31^M
^M
山寨 假货 问题^M
剪贴文章
Book Title\n
- 剪贴文章 位置N | 已添加至 sometime\n
\n
剪贴文章内容\n
每一个摘录都用`==========\n`分割开。
内容提取
书名
<feff>薛兆丰经济学讲义 (薛兆丰)^M
vi re:
^.\([^(]\+\)(
作者
庆余年(精校版) (猫腻)^M
vi re:
([^()]\{-})^M$
位置/页码/添加时间
- 您在位置 #4286 的笔记 | 添加于 2020年1月30日星期四 上午10:26:31^M
vi re:
#\(\d\+-\{0,1}\d\+\).\+\(\d\{4}年\d\{1,2}月\d\{1,2}日\)\(星期.\) \(..\)\(\d\{1,2}:\d\{1,2}:\d\{1,2}\)
group1 - 页码
group2 - xxxx年xx月xx日
group3 - 星期
group4 - 上下午
group5 - 时间
数据结构
dict data structure
book data structure
book =
{
"bookname_xxx": {
"author": "李",
"section1636": {
"content": "张",
"day": "2020年4月3日",
"meridiem": "下午",
"position": "311-311",
"time": "3:00:53",
"type": "HL",
"week": "星期五"
},
"section1651": {
"content": "治",
"day": "2020年4月3日",
"meridiem": "下午",
"position": "514",
"time": "3:43:50",
"type": "NT",
"week": "星期五"
},
"section1814": {
"content": null,
"day": "2020年4月12日",
"meridiem": "下午",
"position": "5186",
"time": "2:20:12",
"type": "BM",
"week": "星期日"
},
...
},
...
}
words datastructure achieved from database **sqlite2**
/Volumes/Kindle/system/vocabulary/vocab.db
table: BOOK_INFO
id - book key, CR!NYRVJ9BT315PKFRS9B9KVB0XF213:6F1EB741
asin x
guid x
lang x zh/en
title - bookname
authors - author
table: LOOKUPS
id x lookups key, CR!NYRVJ9BT315PKFRS9B9KVB0XF213:6F1EB741:xxx
word_key - zh:当
book_key - book key, like CR!NYRVJ9BT315PKFRS9B9KVB0XF213:6F1EB741
dict_key x
pos - position, like AYkJAAAAAAAA:28781, 115907
usage - usage
timestamp - 1566738399454
table: WORDS
id - zh:当
word x 当
stem x
lang - zh/en
category - 0 learning, 100 mastered
timestamp x 1591141963703
profileid x
words_data = [bookinfo, words, lookups]
bookinfo = { 'book_key': {
'bookname':'bookname_xxx',
'author':'author_xxx'},}
words = { 'word_id': {
'word':'xxx',
'category':0},
}
lookups = [['id','word_key','book_key','pos','usage','timestamp'],
['id','word_key','book_key','pos','usage','timestamp'],]
book information grabed from douban
{
"25853071": { # sid
"link":"https://....xxxxx"
"bookname": "庆余年",
"img": "https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2575362797.jpg",
"rate": "8.0",
"author": "猫腻"
},...}
Markdown文本
TYPE | bookname | author | marktime | content
--|--|--|--|--
xx|xx|xx|xx|xx
